
Domains
Artificial Intelligence
Harness AI to create smarter workflows and scalable growth.
View All Artificial Intelligence Coursesicon-aiCertifications
Certification
15 Weeks
Trending
AI Masters Program
Certification
6 Weeks
Trending
Vibe Coding 101: No-code AI Programming.svg)
Certification
48 Hours
Trending
Applied Agentic AI - No Code
Certification
16 Hours
Trending
Generative AI and Prompt Engineering
Certification
8 Weeks
Trending
AI-Powered Product Management
Certification
6 Weeks
Applied Agentic AI Certification
Certification
16 Hours
Generative AI Course for Scrum MastersCertification
16 Hours
Generative AI Course for Project Managers
Certification
16 Hours
Generative AI Course for POPM
Certification
16 Hours
Gen AI Course for Business Analysts
Certification
16 Hours
AI Powered Software Development
Certification
16 Hours
AI-Data Analytics with Power BI
Certification
16 Hours
AI-Driven Digital Marketing Training
Certification
16 Hours
Gen AI for Enterprise Agilist
Advanced Certifications
Masters
Executive Diploma
Executive Diploma in Machine Learning and AI
Executive Diploma
Executive Diploma in Data Science & Artificial Intelligence from IIITBCertification
Chief Technology Officer & AI Leadership ProgrammeMaster's Degree
Master of Science in Machine Learning & AI
Dual Certification
Executive Programme in Generative AI for LeadersCertification
Executive Post Graduate Programme in Applied AI and Agentic AIExecutive PG Program
IIT KGP-Executive PG Certificate in Gen AI and Agentic
Self-Learning Courses
Universal AI by MIT Open LearningAgile Management
Master Agile methodologies for efficient and timely project delivery.
View All Agile Management Coursesicon-refresh-cwCertifications
Scrum Alliance
16 Hours
Best Seller
Certified ScrumMaster (CSM) Certification
Scrum Alliance
16 Hours
Best Seller
Certified Scrum Product Owner (CSPO) Certification
Scaled Agile
16 Hours
Trending
Leading SAFe 6.0 Certification.svg)
Scrum.org
16 Hours
Professional Scrum Master (PSM) Certification
Scaled Agile
16 Hours
AI-Empowered SAFe® 6.0 Scrum MasterPMI
21 Hours
Best Seller
PMI Agile Certified Practitioner (PMI-ACP) Certification
Advanced Certifications
Scaled Agile, Inc.
32 Hours
Recommended
Implementing SAFe 6.0 (SPC) Certification.svg)
Scaled Agile, Inc.
24 Hours
AI-Empowered SAFe® 6 Release Train Engineer (RTE) CourseScaled Agile, Inc.
16 Hours
Trending
SAFe® AI-Empowered Product Owner/Product Manager (6.0)IC Agile
24 Hours
ICP Agile Certified Coaching (ICP-ACC)
Scrum.org
16 Hours
Professional Scrum Product Owner I (PSPO I) Training
Masters
32 Hours
Trending
Agile Management Master's Program
32 Hours
Agile Excellence Master's ProgramOn-Demand Courses
Agile and ScrumRoles
Scrum MasterAccreditation Bodies
Scrum Alliance Scaled Agile, Inc.
Scaled Agile, Inc. Scrum.org
Scrum.org ICAgile
ICAgile PMI
PMI
Top Resources
Scrum TutorialProject Management
Gain expert skills to lead projects to success and timely completion.
View All Project Management Coursesicon-standCertifications
PMI
36 Hours
Best Seller
Project Management Professional (PMP) Certification
Axelos
32 Hours
PRINCE2 Foundation & Practitioner Certification
Axelos
16 Hours
PRINCE2 Foundation Certification
Axelos
16 Hours
PRINCE2 Practitioner Certification
PMI
23 Hours
Best Seller
Certified Associate in Project Management (CAPM)®
PMI
24 Hours
Best Seller
Program Management Professional (PgMP®)
PMI
24 Hours
Best Seller
Portfolio Management Professional (PfMP)®
PMI
30 Hours
Best Seller
Project Management Institute-Risk Management Professional (PMI-RMP)®
Skills
Change ManagementMasters
Job Oriented
45 Hours
Trending
Project Management Master's Program
On-Demand Courses
PRINCE2 Practitioner CourseRoles
Project ManagerAccreditation Bodies
PMIAxelos Scrum Alliance
Scrum AllianceTop Resources
Theories of MotivationCyber Security
Understand how to protect data and systems from threats or disasters.
View All Cyber Security Coursesicon-refresh-cwCertifications
CompTIA
40 Hours
Best Seller
CompTIA Security+
EC-Council
40 Hours
Certified Ethical Hacker (CEH v13) Certification
ISACA
40 Hours
Certified Information Systems Auditor (CISA) Certification
ISACA
40 Hours
Certified Information Security Manager (CISM) Certification
(ISC)²
40 Hours
Certified Information Systems Security Professional (CISSP)
(ISC)²
40 Hours
Certified Cloud Security Professional (CCSP) Certification
16 Hours
Certified Information Privacy Professional - Europe (CIPP-E) Certification
ISACA
16 Hours
COBIT5 Foundation
16 Hours
Payment Card Industry Security Standards (PCI-DSS) Certification
On-Demand Courses
CISSPTop Resources
Laptops for IT SecurityCloud Computing
Learn to harness the cloud to deliver computing resources efficiently.
View All Cloud Computing Coursesicon-cloud-snowingCertifications
AWS
32 Hours
Best Seller
AWS Certified Solutions Architect - Associate
AWS
32 Hours
AWS Cloud Practitioner CertificationAWS
24 Hours
AWS DevOps CertificationMicrosoft
16 Hours
Azure Fundamentals Certification
Microsoft
24 Hours
Best Seller
Azure Administrator CertificationMicrosoft
45 Hours
Recommended
Azure Data Engineer CertificationMicrosoft
32 Hours
Azure Solution Architect CertificationMicrosoft
40 Hours
Azure DevOps CertificationAWS
24 Hours
Systems Operations on AWS Certification TrainingAWS
24 Hours
Developing on AWSMasters
Job Oriented
48 Hours
New
AWS Cloud Architect Masters Program
Roles
Cloud EngineerOn-Demand Courses
AWS Certified Developer Associate - Complete GuideAuthorized Partners of
AWSMicrosoft
Top Resources
Scrum TutorialIT Service Management
Understand how to plan, design, and optimize IT services efficiently.
View All ITSM Coursesicon-git-commitCertifications
Axelos
16 Hours
New
ITIL Foundation (Version 5) CertificationAxelos
16 Hours
Best Seller
ITIL 4 Foundation Certification
Axelos
8 Hours
New
ITIL Foundation Bridge Course (Version 5)Axelos
16 Hours
ITIL Practitioner Certification
PeopleCert
16 Hours
ISO 14001 Foundation Certification
PeopleCert
16 Hours
ISO 20000 CertificationPeopleCert
24 Hours
ISO 27000 Foundation CertificationAxelos
24 Hours
ITIL 4 Specialist: Create, Deliver and Support Training
Axelos
24 Hours
ITIL 4 Specialist: Drive Stakeholder Value TrainingAxelos
16 Hours
ITIL 4 Strategist Direct, Plan and Improve TrainingOn-Demand Courses
ITIL 4 Specialist: Create, Deliver and Support ExamTop Resources
ITIL Practice TestData Science
Unlock valuable insights from data with advanced analytics.
View All Data Science Coursesicon-dataOur Courses
Data Science with PythonRoles
Data ScientistOn-Demand Courses
Data Analysis Using ExcelTop Resources
Machine Learning TutorialDevOps
Automate and streamline the delivery of products and services.
View All DevOps Coursesicon-terminal-squareCertifications
DevOps Institute
16 Hours
Best Seller
DevOps Foundation Certification
CNCF
32 Hours
New
Certified Kubernetes Administrator
Devops Institute
16 Hours
Devops LeaderSkills
KubernetesRoles
DevOps EngineerOn-Demand Courses
CI/CD with Jenkins XGlobal Accreditations
DevOps Institute
Top Resources
Top DevOps ProjectsBI And Visualization
Understand how to transform data into actionable, measurable insights.
View All BI And Visualization Coursesicon-microscopeBI and Visualization Tools
Certification
24 Hours
Recommended
Tableau Certification
Certification
24 Hours
Data Visualization with Tableau Certification
Microsoft
24 Hours
Best Seller
Microsoft Power BI Certification
TIBCO
36 Hours
TIBCO Spotfire Training
Certification
30 Hours
Data Visualization with QlikView CertificationCertification
16 Hours
Sisense BI Certification
On-Demand Courses
Data Visualization Using Tableau TrainingTop Resources
Python Data Viz LibsWeb Development
Learn to create user-friendly, fast, and dynamic web applications.
View All Web Development Coursesicon-codeOur Courses
ReactOn-Demand Courses
Angular TrainingTop Resources
Top HTML ProjectsBlockchain
Understand how transactions and databases work in blockchain technology.
View All Blockchain Coursesicon-stop-squareBlockchain Certifications
40 Hours
Blockchain Professional Certification
32 Hours
Blockchain Solutions Architect Certification
32 Hours
Blockchain Security Engineer Certification
24 Hours
Blockchain Quality Engineer Certification
5+ Hours
Blockchain 101 Certification
On-Demand Courses
NFT Essentials 101: A Beginner's GuideTop Resources
Blockchain Interview QsProgramming
Learn to code efficiently and design software that solves problems.
View All Programming Coursesicon-codeSkills
Python CertificationInterview Prep
Career Accelerator
3 Months
Software Engineer Interview Prep
On-Demand Courses
Data Structures and Algorithms with JavaScriptTop Resources
Python Tutorial- Home
- Interview Questions
- Big Data
- Kafka Interview Questions and Answers
Big Data
Kafka Interview Questions and Answers
4.5 Rating 60 Questions 30 mins read293 Readers

Introduction
1. How is the Kafka messaging system different from other messaging framework?
Kafka is a messaging framework developed by apache foundation, which is to create the create the messaging system along with can provide fault tolerant cluster along with the low latency system, to ensure end to end delivery.
Below are the bullet points:
- Kafka is a messaging system, which has provided fault tolerant capability to prevent the message loss.
- Design on public-subscribe model.
- Kafka cab support both Java and Scala.
- Kafka was originated at LinkedIn and later became an open sourced Apache project in 2011
- Work seamlessly with spark and other big data technology.
- Support cluster mode operation
- Kafka messaging system can be use for web service architecture or big data architecture.
- Kafka ease to code and configure as compare to other messaging framework.
Kafka required other component such as the zookeeper to create a cluster and act as a coordination server
2. What are the key Features of Kafka?
Kafka provide a reliable delivery for messages from sender to receiver apart from that it has other key features as well.
- Kafka is designed for achieving high throughput and fault tolerant messaging services.
- Kafka provides build in patriation called as a Topic.
- Also provide the feature of replication.
- Kafka provides a queue, which can handle the high volume of data and eventually transfer the message from one sender to receiver.
- Kafka also persisted the message in the disk along with has ability to replicate the messages across the cluster
- Kafka work with zookeeper for coordination and synchronization with other services.
- Kafka has good inbuilt support Apache Spark.
To utilize all this key feature, we need to configure the Kafka cluster properly along with the zookeeper configuration.
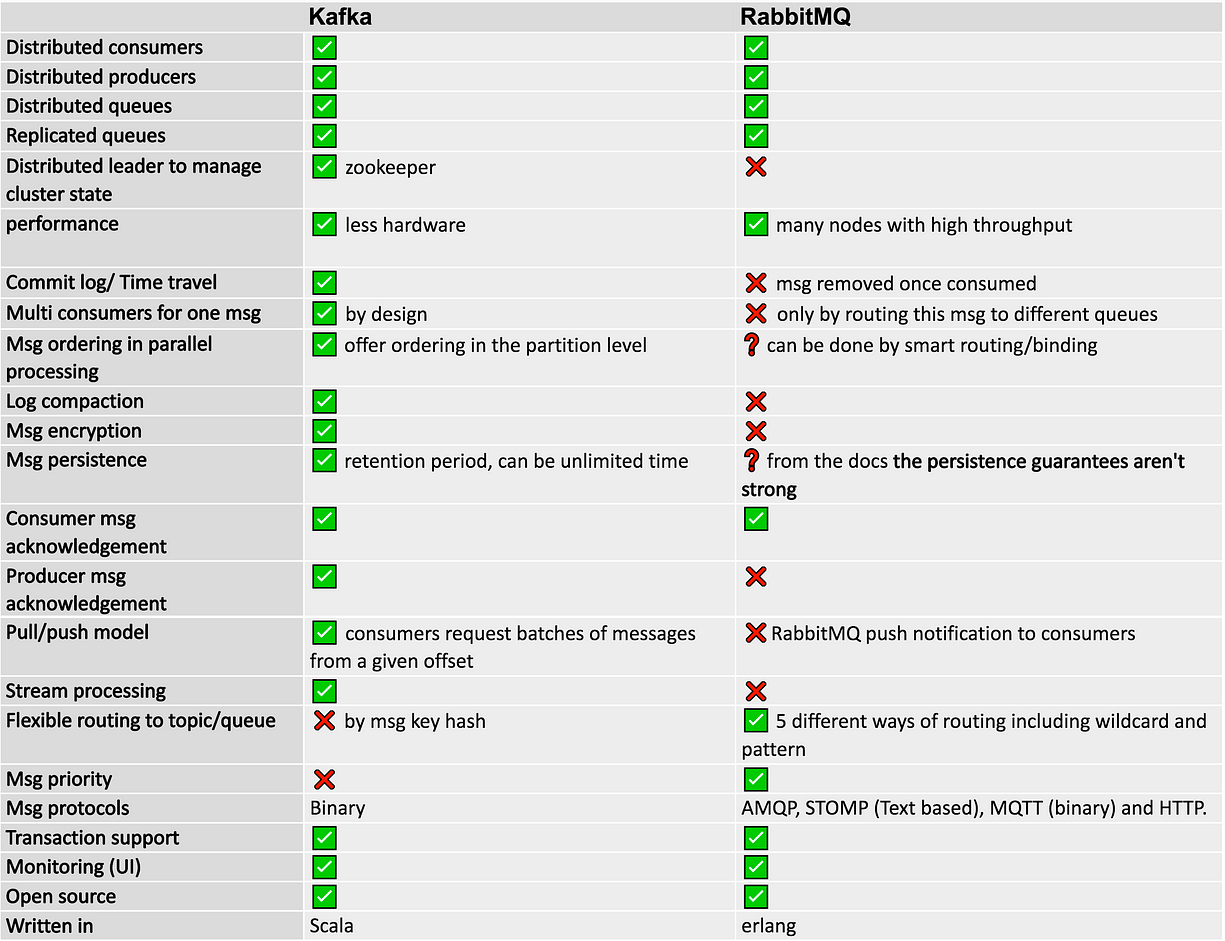
3. Benefits of using Kafka than other messaging services like JMS, RabbitMQ doesn’t provide?
Now a days kafka is a key messaging framework, not because of its features even for reliable transmission of messages from sender to receiver, however, below are the key points which should consider.
- Reliability − Kafka provides a reliable delivery from publisher to a subscriber with zero message loss..
- Scalability −Kafka achieve this ability by using clustering along with the zookeeper coordination server
- Durability −By using distributed log, the messages can persist on disk.
- Performance − Kafka provides high throughput and low latency across the publish and subscribe application.
Considering the above features Kafka is one of the best options to use in Bigdata Technologies to handle the large volume of messages for a smooth delivery.
This is one of the most frequently asked Apache Kafka interview questions for freshers in recent times.
4. What is the real-world use case of Kafka, which makes different from other messaging framework?
There is plethora of use case, where Kafka fit into the real work application, however I listed below are the real work use case which is frequently using.
- Metrics: Use for monitoring operation data, which can use for analysis or doing statistical operation on gather the data from distributed system
- Log Aggregation solution: can be used across an organization to collect logs from multiple services, which consume by consumer services to perform the analytical operation.
- Stream Processing: Kafka’s strong durability is also very useful in the context of stream processing.
- Asynchronous communication: In microservices, keeping this huge system synchronous is not desirable, because it can render the entire application unresponsive. Also, it can defeat the whole purpose of dividing into microservices in the first place. Hence, having Kafka at that time makes the whole data flow easier. Because it is distributed, highly fault-tolerant and it has constant monitoring of broker nodes through services like Zookeeper. So, it makes it efficient to work.
- Chat bots: Chat bots is one of the popular use cases when we require reliable messaging services for a smooth delivery.
- Multi-tenant solution. Multi-tenancy is enabled by configuring which topics can produce or consume data. There are also operations support for quotas
Above are the use case where predominately require a Kafka framework, apart from that there are other cases which depends upon the requirement and design.
5. Why we need Kafka rather than other messaging services?
Let’s talk about some modern source of data now a days which is a data—transactional data such as orders, inventory, and shopping carts — is being augmented with things such as clicking, likes, recommendations and searches on a web page. All this data is deeply important to analyze the consumers behaviors, and it can feed a set of predictive analytics engines that can be the differentiator for companies.
- Support low latency message delivery.
- Handling the real time traffic.
- Assurance for fault tolerant.
- Easy to integrate with Spark application to process a high volume of messaging data.
- Has an ability to create a cluster of messaging container which monitor and supervise by coordination server like Zookeeper.
So, when we need to handle this kind of volume of data, we need Kafka to solve this problem.



1. Let’s say that a producer is writing records to a Kafka topic at 10000 messages/sec while the consumer is only able to read 2500 messages per second. What are the different ways in which you can scale up your consumer?
The answer to this question encompasses two main aspects – Partitions in a topic and Consumer Groups.
A Kafka topic is divided into partitions. The message sent by the producer is distributed among the topic’s partitions based on the message key. Here we can assume that the key is such that messages would get equally distributed among the partitions.
Consumer Group is a way to bunch together consumers so as to increase the throughput of the consumer application. Each consumer in a group latches to a partition in the topic. i.e. if there are 4 partitions in the topic and 4 consumers in the group then each consumer would read from a single partition. However, if there are 6 partitions and 4 consumers, then the data would be read in parallel from 4 partitions only. Hence its ideal to maintain a 1 to 1 mapping of partition to the consumer in the group.
Now in order to scale up processing at the consumer end, two things can be done:
- No of partitions in the topic can be increased (say from existing 1 to 4).
- A consumer group can be created with 4 instances of the consumer attached to it.
Doing this would help read data from the topic in parallel and hence scale up the consumer from 2500 messages/sec to 10000 messages per second.
Don't be surprised if this question pops up as one of the top interview questions on Kafka in your next interview.
2. What is Dumb Broker/Smart Producer vs Smart Broker/Dumb Consumer? What model does Apache Kafka follow?
Dumb broker/Smart producer implies that the broker does not attempt to track which messages have been read by each consumer and only retain unread messages; rather, the broker retains all messages for a set amount of time, and consumers are responsible to track what all messages have been read.
Apache Kafka employs this model only wherein the broker does the work of storing messages for a time (7 days by default), while consumers are responsible for keeping track of what all messages they have read using offsets.
The opposite of this is the Smart Broker/Dumb Consumer model wherein the broker is focused on the consistent delivery of messages to consumers. In such a case, consumers are dumb and consume at a roughly similar pace as the broker keeps track of consumer state. This model is followed by RabbitMQ.
3. What is meant by fault tolerance? How does Kafka provide fault tolerance?
Kafka is a distributed system wherein data is stored across multiple nodes in the cluster. There is a high probability that one or more nodes in the cluster might fail. Fault tolerance means that the data is the system is protected and available even when some of the nodes in the cluster fail.
One of the ways in which Kafka provides fault tolerance is by making a copy of the partitions. The default replication factor is 3 which means for every partition in a topic, two copies are maintained. In case one of the broker fails, data can be fetched from its replica. This way Kafka can withstand N-1 failures, N being the replication factor.
Kafka also follows the leader-follower model. For every partition, one broker is elected as the leader while others are designated, followers. A leader is responsible for interacting with the producer/consumer. If the leader node goes down, then one of the remaining followers is elected as a leader.
Kafka also maintains a list of In Sync replicas. Say the replication factor is 3. That means there will be a leader partition and two follower partitions. However, the followers may not be in sync with the leader. The ISR shows the list of replicas that are in sync with the leader.
4. What is an offset in Kafka? What are the different ways to commit an offset? Where does Kafka maintain offset?
As we already know, a Kafka topic is divided into partitions. The data inside each partition is ordered and can be accessed using an offset. Offset is a position within a partition for the next message to be sent by the consumer. There are two types of offsets maintained by Kafka:
Current Offset
- It is a pointer to the last record that Kafka has sent in the most recent poll. This offset thus ensures that the consumer does not get the same record twice.
Committed Offset
- It is a pointer to the last record that a consumer has successfully processed. It plays an important role in case of partition rebalancing – when a new consumer gets assigned to a partition – the new consumer can use committed offset to determine where to start reading records from
There are two ways to commit an offset:

- Auto-commit: Enabled by default and can be turned off by setting property – enable.auto.commit - to false. Though convenient, it might cause duplicate records to get processed.
- Manual-commit: This implies that auto-commit has been turned off and offset will be manually committed when the record has been processed.
Prior to Kafka v0.9, Zookeeper was being used to store topic offset, however from v0.9 onwards, the information regarding offset on a topic’s partition is stored on a topic called _consumer_offsets.
5. What is meant by Kafka producer Acknowledgement? What are the different types of acknowledgment settings provided by Kafka?
An ack or acknowledgment is sent by a broker to the producer to acknowledge receipt of the message. Ack level can be set as a configuration parameter in the Producer and it defines the number of acknowledgments the producer requires the leader to have received before considering a request complete. The following settings are allowed:
- acks=0
In this case, the producer doesn’t wait for any acknowledgment from the broker. No guarantee can be that the broker has received the record.
- acks=1
In this case, the leader writes the record to its local log file and responds back without waiting for acknowledgment from all its followers. In this case, the message can get lost only if the leader fails just after acknowledging the record but before the followers have replicated it, then the record would be lost.
- acks=all
In this case, a set leader waits for all entire sets of in sync replicas to acknowledge the record. This ensures that the record does not get lost as long as one replica is alive and provides the strongest possible guarantee. However it also considerably lessens the throughput as a leader must wait for all followers to acknowledge before responding back.
acks=1 is usually the preferred way of sending records as it ensures receipt of record by a leader, thereby ensuring high durability and at the same time ensures high throughput as well. For highest throughput set acks=0 and for highest durability set acks=all.






1. What is Kafka cluster and what is the key benefits of creating Kafka cluster?
- Kafka cluster is a group of more than one broker.
- Kafka cluster has a zero downtime, when we do the expansion of cluster.
- This cluster use to manage the persistence and replication of message data.
- This cluster offer’s strong durability due to cluster centric design.
- In the Kafka cluster, one of the brokers serves as the controller, which is responsible for managing the states of partitions and replicas and for performing administrative tasks like reassigning partitions.
2. How producer works in the Kafka?
Producer is a client who send or publish the record. Producer applications write data to topics and consumer applications read from topics.
- Producer is a publisher to publish the message in one or more Kafka topic.
- Producer sends data to the broker service.
- Whenever the producer publishes the message, the broker just appends the message to the last segment of the partition.
- Producer can send the message as per the desire topic as well.
Messages sent by a producer to a topic partition will be appended in the order they are sent. That is, if a record M1 is sent by the same producer as a record M2, and M1 is sent first, then M1 will have a lower offset than M2 and appear earlier in the log.
3. What is a role of consumer in Kafka?
Consumer is a subscriber who consume the messages which predominantly stores in a partition. Consumer is a separate process and can be separate application altogether which run in individual machine.
- Consumer can subscribe one and more than one topic.
- Consumer also maintain the counter for message as per the offset value.
- If consumer acknowledge a specific message offset, that means it consume all the previous message.
- Consumer work on asynchronous pull request to the broker to ready with byte or data for consumption.
- Consumer offset value is notified by zookeeper.
If all the consumer falls into the same consumer group, then by using load balancer the message will be distributed over the consumer instances, if consumer instances falls in different group, than each message will be broadcast to all consumer group.
4. What is the working principle of Kafka?
The working principle of Kafka follows the below order.
- Producers send message to a topic at regular intervals.
- Broker in kafka responsible to stores the messages which is available in partitions configured for that topic.
- Kafka ensure that if producer publish the two messages, than both the message should be accept by consumer.
- Consumer pull the message from the allocated topic.
- Once consumer digest the topic than Kafka push the offset value to the zookeeper.
- Consumer continuously sending the signal to Kafka approx every 100ms, waiting for the messages.
- Consumer send the acknowledgement ,when message get received.
- When Kafka receives an acknowledgement, it modified the offset value to the new value and send to the Zookeeper. Zookeeper maintain this offset value so that consumer can read next message correctly even during server outrages.
- This flow is continuing repeating until the request will be live.
5. What are the key advantages of using Kafka?
Apart from other benefits, below are the key advantages of using Kafka messaging framework.
- Low Latency.
- High throughput.
- Fault tolerant.
- Durability.
- Scalability.
- Support for real time streaming
- High concurrency.
- Message broker capabilities.
- Persistent capability.
Considering all the above advantages, Kafka is one of the most popular frameworks utilize in Micro service architecture, Big Data architecture, Enterprise Integration architecture, publish-subscribe architecture.
Expect to come across this, one of the most important Kafka interview questions for experienced professionals in data management, in your next interviews.




























{kind=link}
Want to Know More?

10% OFF
Description
Recommended Courses
