
Domains
Artificial Intelligence
Harness AI to create smarter workflows and scalable growth.
View All Artificial Intelligence Coursesicon-aiCertifications
Certification
15 Weeks
Trending
AI Masters Program
Certification
6 Weeks
Trending
Vibe Coding 101: No-code AI Programming.svg)
Certification
48 Hours
Trending
Applied Agentic AI - No Code
Certification
16 Hours
Trending
Generative AI and Prompt Engineering
Certification
8 Weeks
Trending
AI-Powered Product Management
Certification
6 Weeks
Applied Agentic AI Certification
Certification
16 Hours
Generative AI Course for Scrum MastersCertification
16 Hours
Generative AI Course for Project Managers
Certification
16 Hours
Generative AI Course for POPM
Certification
16 Hours
Gen AI Course for Business Analysts
Certification
16 Hours
AI Powered Software Development
Certification
16 Hours
AI-Data Analytics with Power BI
Certification
16 Hours
AI-Driven Digital Marketing Training
Certification
16 Hours
Gen AI for Enterprise Agilist
Advanced Certifications
Masters
Executive Diploma
Executive Diploma in Machine Learning and AI
Executive Diploma
Executive Diploma in Data Science & Artificial Intelligence from IIITBCertification
Chief Technology Officer & AI Leadership ProgrammeMaster's Degree
Master of Science in Machine Learning & AI
Dual Certification
Executive Programme in Generative AI for LeadersCertification
Executive Post Graduate Programme in Applied AI and Agentic AIExecutive PG Program
IIT KGP-Executive PG Certificate in Gen AI and Agentic
Self-Learning Courses
Universal AI by MIT Open LearningAgile Management
Master Agile methodologies for efficient and timely project delivery.
View All Agile Management Coursesicon-refresh-cwCertifications
Scrum Alliance
16 Hours
Best Seller
Certified ScrumMaster (CSM) Certification
Scrum Alliance
16 Hours
Best Seller
Certified Scrum Product Owner (CSPO) Certification
Scaled Agile
16 Hours
Trending
Leading SAFe 6.0 Certification.svg)
Scrum.org
16 Hours
Professional Scrum Master (PSM) Certification
Scaled Agile
16 Hours
AI-Empowered SAFe® 6.0 Scrum MasterPMI
21 Hours
Best Seller
PMI Agile Certified Practitioner (PMI-ACP) Certification
Advanced Certifications
Scaled Agile, Inc.
32 Hours
Recommended
Implementing SAFe 6.0 (SPC) Certification.svg)
Scaled Agile, Inc.
24 Hours
AI-Empowered SAFe® 6 Release Train Engineer (RTE) CourseScaled Agile, Inc.
16 Hours
Trending
SAFe® AI-Empowered Product Owner/Product Manager (6.0)IC Agile
24 Hours
ICP Agile Certified Coaching (ICP-ACC)
Scrum.org
16 Hours
Professional Scrum Product Owner I (PSPO I) Training
Masters
32 Hours
Trending
Agile Management Master's Program
32 Hours
Agile Excellence Master's ProgramOn-Demand Courses
Agile and ScrumRoles
Scrum MasterAccreditation Bodies
Scrum Alliance Scaled Agile, Inc.
Scaled Agile, Inc. Scrum.org
Scrum.org ICAgile
ICAgile PMI
PMI
Top Resources
Scrum TutorialProject Management
Gain expert skills to lead projects to success and timely completion.
View All Project Management Coursesicon-standCertifications
PMI
36 Hours
Best Seller
Project Management Professional (PMP) Certification
Axelos
32 Hours
PRINCE2 Foundation & Practitioner Certification
Axelos
16 Hours
PRINCE2 Foundation Certification
Axelos
16 Hours
PRINCE2 Practitioner Certification
PMI
23 Hours
Best Seller
Certified Associate in Project Management (CAPM)®
PMI
24 Hours
Best Seller
Program Management Professional (PgMP®)
PMI
24 Hours
Best Seller
Portfolio Management Professional (PfMP)®
PMI
30 Hours
Best Seller
Project Management Institute-Risk Management Professional (PMI-RMP)®
Skills
Change ManagementMasters
Job Oriented
45 Hours
Trending
Project Management Master's Program
On-Demand Courses
PRINCE2 Practitioner CourseRoles
Project ManagerAccreditation Bodies
PMIAxelos Scrum Alliance
Scrum AllianceTop Resources
Theories of MotivationCyber Security
Understand how to protect data and systems from threats or disasters.
View All Cyber Security Coursesicon-refresh-cwCertifications
CompTIA
40 Hours
Best Seller
CompTIA Security+
EC-Council
40 Hours
Certified Ethical Hacker (CEH v13) Certification
ISACA
40 Hours
Certified Information Systems Auditor (CISA) Certification
ISACA
40 Hours
Certified Information Security Manager (CISM) Certification
(ISC)²
40 Hours
Certified Information Systems Security Professional (CISSP)
(ISC)²
40 Hours
Certified Cloud Security Professional (CCSP) Certification
16 Hours
Certified Information Privacy Professional - Europe (CIPP-E) Certification
ISACA
16 Hours
COBIT5 Foundation
16 Hours
Payment Card Industry Security Standards (PCI-DSS) Certification
On-Demand Courses
CISSPTop Resources
Laptops for IT SecurityCloud Computing
Learn to harness the cloud to deliver computing resources efficiently.
View All Cloud Computing Coursesicon-cloud-snowingCertifications
AWS
32 Hours
Best Seller
AWS Certified Solutions Architect - Associate
AWS
32 Hours
AWS Cloud Practitioner CertificationAWS
24 Hours
AWS DevOps CertificationMicrosoft
16 Hours
Azure Fundamentals Certification
Microsoft
24 Hours
Best Seller
Azure Administrator CertificationMicrosoft
45 Hours
Recommended
Azure Data Engineer CertificationMicrosoft
32 Hours
Azure Solution Architect CertificationMicrosoft
40 Hours
Azure DevOps CertificationAWS
24 Hours
Systems Operations on AWS Certification TrainingAWS
24 Hours
Developing on AWSMasters
Job Oriented
48 Hours
New
AWS Cloud Architect Masters Program
Roles
Cloud EngineerOn-Demand Courses
AWS Certified Developer Associate - Complete GuideAuthorized Partners of
AWSMicrosoft
Top Resources
Scrum TutorialIT Service Management
Understand how to plan, design, and optimize IT services efficiently.
View All ITSM Coursesicon-git-commitCertifications
Axelos
16 Hours
New
ITIL Foundation (Version 5) CertificationAxelos
16 Hours
Best Seller
ITIL 4 Foundation Certification
Axelos
8 Hours
New
ITIL Foundation Bridge Course (Version 5)Axelos
16 Hours
ITIL Practitioner Certification
PeopleCert
16 Hours
ISO 14001 Foundation Certification
PeopleCert
16 Hours
ISO 20000 CertificationPeopleCert
24 Hours
ISO 27000 Foundation CertificationAxelos
24 Hours
ITIL 4 Specialist: Create, Deliver and Support Training
Axelos
24 Hours
ITIL 4 Specialist: Drive Stakeholder Value TrainingAxelos
16 Hours
ITIL 4 Strategist Direct, Plan and Improve TrainingOn-Demand Courses
ITIL 4 Specialist: Create, Deliver and Support ExamTop Resources
ITIL Practice TestData Science
Unlock valuable insights from data with advanced analytics.
View All Data Science Coursesicon-dataOur Courses
Data Science with PythonRoles
Data ScientistOn-Demand Courses
Data Analysis Using ExcelTop Resources
Machine Learning TutorialDevOps
Automate and streamline the delivery of products and services.
View All DevOps Coursesicon-terminal-squareCertifications
DevOps Institute
16 Hours
Best Seller
DevOps Foundation Certification
CNCF
32 Hours
New
Certified Kubernetes Administrator
Devops Institute
16 Hours
Devops LeaderSkills
KubernetesRoles
DevOps EngineerOn-Demand Courses
CI/CD with Jenkins XGlobal Accreditations
DevOps Institute
Top Resources
Top DevOps ProjectsBI And Visualization
Understand how to transform data into actionable, measurable insights.
View All BI And Visualization Coursesicon-microscopeBI and Visualization Tools
Certification
24 Hours
Recommended
Tableau Certification
Certification
24 Hours
Data Visualization with Tableau Certification
Microsoft
24 Hours
Best Seller
Microsoft Power BI Certification
TIBCO
36 Hours
TIBCO Spotfire Training
Certification
30 Hours
Data Visualization with QlikView CertificationCertification
16 Hours
Sisense BI Certification
On-Demand Courses
Data Visualization Using Tableau TrainingTop Resources
Python Data Viz LibsWeb Development
Learn to create user-friendly, fast, and dynamic web applications.
View All Web Development Coursesicon-codeOur Courses
ReactOn-Demand Courses
Angular TrainingTop Resources
Top HTML ProjectsBlockchain
Understand how transactions and databases work in blockchain technology.
View All Blockchain Coursesicon-stop-squareBlockchain Certifications
40 Hours
Blockchain Professional Certification
32 Hours
Blockchain Solutions Architect Certification
32 Hours
Blockchain Security Engineer Certification
24 Hours
Blockchain Quality Engineer Certification
5+ Hours
Blockchain 101 Certification
On-Demand Courses
NFT Essentials 101: A Beginner's GuideTop Resources
Blockchain Interview QsProgramming
Learn to code efficiently and design software that solves problems.
View All Programming Coursesicon-codeSkills
Python CertificationInterview Prep
Career Accelerator
3 Months
Software Engineer Interview Prep
On-Demand Courses
Data Structures and Algorithms with JavaScriptTop Resources
Python TutorialBig Data Analytics Training
Big Data Analyst Salary
Learn about how much you can earn as a Big Data Analyst
 31,802+ Enrolled
31,802+ Enrolled
Prerequisites
There are no specific prerequisites required to learn Big Data. Any one can do big data courses.

Big Data Analytics Highlights
30 Hours of Intensive Training on Big Data and its Frameworks
Industry Case Studies and Exercises for Enhanced Learning
Hands-On Training by Industry Experts
Gain Technical Expertise in Big Data Analytics
In-depth Questionnaires with Projects for Practice
Complimentary Access to 100+ e-Learning Courses
Big Data analytics is the process of gathering, managing, and analyzing large sets of data (Big Data) to uncover patterns and other useful information. These patterns are a minefield of information and analysing them provide several insights that can be used by organizations to make business decisions. This analysis is essential for large organizations like Facebook who manage over a billion users every day, and use the data collected to help provide a better user experience.
Similarly, LinkedIn provides its users with millions of personalized suggestions on a regular basis. LinkedIn does it with the help of components like HDFS features and MapReduce in Big Data Analytics. Big Data has thus become an indispensable part of technology and our lives; and big data analyses provides solutions that are quick and require reduced effort to generate. It is no wonder then that big data has spread like wild fire and so have the solutions for its analyses.
According to a recent McKinsey report the demand for ‘Big Data’ professionals could outpace the supply by 50 to 60 percent in the coming years, and U.S.-based companies will be looking to hire over 1.5 million managers and big data analysts with expertise on how big data can be applied. Big Data investments have also sky rocketed, with several top profile companies spending their resources on Big Data related research and hiring big data analysts to change their technology landscape.
An IBM listing states that the demand for data science and analytics is expected to grow from 3,64,000 to nearly 27,20,000 by 2020. According to a recent study done by Forrester, companies only analyze about 12% of the data at their disposal. 88% of the data is ignored, mainly due to the lack of analytics and repressive data silos. Imagine the market share of big data if all companies start analysing 100% of the data available to them. Hence the conclusion is that there is no time like now to start investing in a career in big data. It is paramount that developers upskill themselves with analytical skills and get ready to take a share of the big data career pie.
Benefits
Big data analytics certification is growing in demand and is most relevant in data science today than in other fields. The field of data analytics is new and there are not enough professionals with the right skills. Hence, the credibility of big data analytics certification promises many growth opportunities for organizations as well as individuals in the booming field of data science.
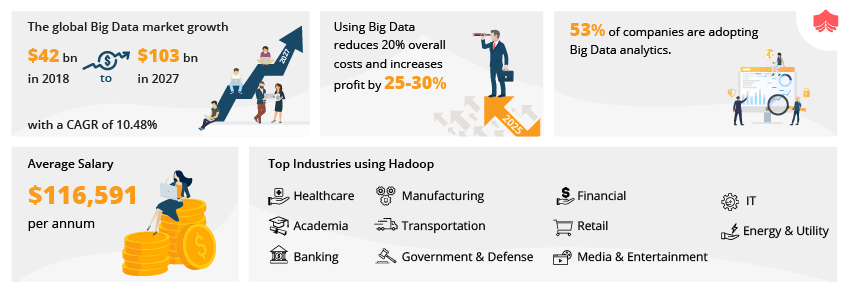
Many big companies like Google, Apple, Adobe, and so on are investing in Big Data. Let’s take a look at the benefits of Big Data that organizations and individuals are experiencing:
Benefits for Individuals
An individual with Big Data analytics skills can make decisions more effectively
- Based on the IBM survey, the Big Data analytics job market is expected to grow by 15% in the year 2020
- According to Glassdoor, Big Data Engineers are earning an average of $116,591 per annum
- An individual with Big Data skills can earn a better salary, good career growth, and more chances of getting hired by top companies
Benefits for Organizations
- Big Data allows organizations to understand consumer needs and make informed decisions
- Big data tools can identify efficient ways of doing business through sentiment analysis
- Businesses can get ahead of the competition by better understanding market conditions
- With Big Data Analytics, organizations understand ongoing trends and develop products accordingly.
How Much Does A Big Data Analyst Earn?
Salaries of Big Data Analysts across the globe
When the entire world is dependent on data, the Big Data Analyst profile plays a pivotal role in driving various businesses towards success. Now, let’s compare the salary of a Big Data Analyst in various countries in the following chart:
The above data can be compared more clearly through the following figure in order to compare the country-wise earning of a Big Data Analyst:

| Country Name | Currency | Salary (per annum) |
| India | Rupees (INR) | 4,14,628 |
| USA | Dollar ($) | 59,546 |
| UK | Pound Sterling (£) | 26,179 |
| Canada | Canadian Dollar (C$) | 55,004 |
The above data can be compared more clearly through the following figure in order to compare the country-wise earning of a Big Data Analyst:

(Fig: 1)
The above figure shows us that a Big Data Analyst based in the US earns a higher salary compared to the counterparts based in India, UK, and Canada. Now, let’s try to compare the salary earned by the Big Data Analysts across the globe based on experience through the following chart:
Country Name | Experience | Currency | Salary (per annum) |
India | Entry-level | Rupees (INR) | 3,21,470 |
Mid-career | 6,12,850 | ||
Experienced | 9,97,193 | ||
USA | Entry-level | Dollar ($) | 53,958 |
Mid-career | 66,347 | ||
Experienced | 68,510 | ||
UK | Entry-level | Pound Sterling (£) | 23,982 |
Mid-career | 30,226 | ||
Experienced | 33,202 | ||
Canada | Entry-level | Canadian Dollar (C$) | 49,325 |
Mid-career | 64,292 | ||
Experienced | 69,216 |
Now, let’s try to analyze the above data with the help of the following figure:

(Fig: 2)
In Fig:2, we can draw a clear comparison between the experience-wise salary that a Big Data Analyst earns in India, USA, UK, and Canada. The figure makes it clear that the highest salary for the profile is earned in the US by the experienced Big Data Analysts. Moreover, the above chart further enables you to make a clear distinction between entry-level, mid-career and experienced Big Data Analyst.
Company-wise salary
So, that was about the salaries that a Big Data Analyst earns based on the location and experience. But the major question that arises here is, which are the companies that pay the highest salaries in the above countries. The following table will help you to check the salary paid by the top companies in India:
| Company Name | Salary (in Rupees per annum) |
Tata Consultancy Services | 4,97,336 |
Cognizant Technology Solutions | 5,21,638 |
Accenture | 5,34,210 |
Tech Mahindra | 4,62,673 |
IBM | 4,30,624 |
Amazon | 5,84,937 |
Fig: 1 & 2 give us a clear picture of the fact that the earning of a Big Data Analyst is more in the US compared to other nations. Now let’s take a look at the salary paid to Big Data Analysts by companies based in the US.
| Company Name | Salary (in US Dollars per annum) |
CITI | 104,000 |
HP Inc. | 77,000 |
Auto Club of Southern California | 69,000 |
JB Micro | 110,000 |
Now, let’s check out the salaries paid by companies to Big Data Analysts based in United Kingdoms.
| Company Name | Salary (in Pound Sterlings per annum) |
Bloomberg L.P. | 42,515 |
Her Majesty’s Revenue & Customs | 32,015 |
Sport England | 46,296 |
Sky | 41,786 |
The following table will help you to identify the salary paid by the companies based in Canada to the Big Data Analysts while enabling you to compare the same with the other countries:
Company NameSalary (in Canadian Dollars per annum)TD
67,699
Scotiabank
59,938
Aimia
67,663
RBC
56,545
Rogers Communications
55,000
Project
Recommendation Engine
Creating Recommendation system for Online Video Channels with the Historical Data using Cubing Comparing with the Benchmark Values.
Sentimental Analytics
Creating Sentimental Analytics by Downloading the Tweets from Twitter and Feeds the trending data to the Application.
Clickstream Analytics
Performing Clickstream Analytics on the Application data and engaging Customers by Customizing the Articles to the Customer for a UK Web Based Channel.
Who Can Attend?
- Data Architects
- Data Scientists
- Developers
- Data Analysts
- BI Analysts
- BI Developers
- SAS Developers
- Project Managers
- Mainframe and Analytics Professionals
- Professionals who want to acquire knowledge on Big Data

Learning Objectives
Interact with instructors in real-time— listen, learn, question and apply. Our instructors are industry experts and deliver hands-on learning.
Our courseware is always current and updated with the latest tech advancements. Stay globally relevant and empower yourself with the latest training!
Learn theory backed by practical case studies, exercises, and coding practice. Get skills and knowledge that can be applied effectively.
Learn from the best in the field. Our mentors are all experienced professionals in the fields they teach.
Learn concepts from scratch, and advance your learning through step-by-step guidance on tools and techniques.
Get reviews and feedback on your final projects from professional developers.
Learn about Big Data
Understand the Fundamentals
Learn Pig framework
Understand the Hive framework
Perform Real-time analysis
Choose the best tool
Curriculum
1. Introducing Big Data & Hadoop
Learning Objective:
You will get introduced to real-world problems with Big data and will learn how to solve those problems with state-of-the-art tools. Understand how Hadoop offers solutions to traditional processing with its outstanding features. You will get to Know Hadoop background and different distributions of Hadoop available in the market. Prepare the Unix Box for the training.
Topics:
1.1 Big Data Introduction
- What is Big Data
- Data Analytics
- Big Data Challenges
- Technologies supported by big data
1.2 Hadoop Introduction
- What is Hadoop?
- History of Hadoop
- Basic Concepts
- Future of Hadoop
- The Hadoop Distributed File System
- Anatomy of a Hadoop Cluster
- Breakthroughs of Hadoop
- Hadoop Distributions:
- Apache Hadoop
- Cloudera Hadoop
- Horton Networks Hadoop
- MapR Hadoop
Hands On:
Installation of Virtual Machine using VMPlayer on Host Machine. And work with Some basics Unix Commands needs for Hadoop.
2. Hadoop Daemon Processes
Learning Objective:
You will learn what are the different Daemons and their functionality at a high level.
Topics:
- Name Node
- Data Node
- Secondary Name Node
- Job Tracker
- Task Tracker
Hands On:
Creates a Unix Shell Script to run all the deamons at one time.
Starting HDFS and MR separately.
3. HDFS (Hadoop Distributed File System)
Learning Objective:
You will get to know how to Write and Read files in HDFS. Understand how Name Node, Data Node and Secondary Name Node take part in HDFS Architecture. You will also know different ways of Accessing HDFS data.
Topics:
- Blocks and Input Splits
- Data Replication
- Hadoop Rack Awareness
- Cluster Architecture and Block Placement
- Accessing HDFS
- JAVA Approach
- CLI Approach
Hands On:
Writes a shell Script which write and read Files in HDFS. Changes Replication factor at three levels. Use Java for working with HDFS.
Writes different HDFS Commands and also Admin Commands.
4. Hadoop Installation Modes and HDFS
Learning Objective:
You will learn different modes of Hadoop, understand Pseudo Mode from scratch and work with Configuration. You will learn functionality of different HDFS operation and Visual Representation of HDFS Read and Write actions with their Daemons Namenode and Data Node.
Topics:
- Local Mode
- Pseudo-distributed Mode
- Fully distributed mode
- Pseudo Mode installation and configurations
- HDFS basic file operations
Hands On:Install Virtual Box Manager and install Hadoop in Pseudo distributed mode. Changes the different Configuration files required for Pseudo Distributed mode. Performs different File Operations on HDFS.
FAQ's
1. What are the prerequisites for learning Big Data Analytics?
There are no prerequisites for attending this course.
2. Why should I learn Big Data Analytics?
Big Data analytics is important for companies and individuals to utilise data in the most efficient manner to cut costs. Tools such as Hadoop can help identify new sources of Data to help businesses to make quick decisions, understand market trends and develop new products
3. Who should do the Big Data Analytics course?
- Freshers who would like to build their career in the world of data (this is an introductory course).
- Those who want to learn Hadoop and Spark
- Software Developers and Architects
- Analytics Professionals
- Senior IT professionals
- Testing and Mainframe professionals
- Data Management Professionals
- Business Intelligence Professionals
- Project Managers
- Aspiring Data Scientists
- Graduates looking to build a career in Big Data Analytics
1. How is the Big Data Analytics training conducted?
All of the training programs conducted by us are interactive in nature and fun to learn as a great amount of time is spent on hands-on practical training, use case discussions, and quizzes. An extensive set of collaborative tools and techniques are used by our trainers which will improve your online training experience.
The Big Data Analytics training conducted at KnowledgeHut is customized according to the preferences of the learner. The training is conducted in three ways:
Online Classroom training: You can learn from anywhere through the most preferred virtual live and interactive training
Self-paced learning: This way of learning will provide you lifetime access to high-quality, self-paced e-learning materials designed by our team of industry experts
Team/Corporate Training: In this type of training, a company can either pick an employee or entire team to take online or classroom training. Flexible pricing options, standard Learning Management System (LMS), and enterprise dashboard are the add-on features of this training. Moreover, you can customize your curriculum based on your learning needs and also get post-training support from the expert during your real-time project implementation.
2. How long will it take to complete the course?
The sessions that are conducted include 30 hours of live sessions, with 15 hours MCQs and 8 hours of Assignments and 20 hours of hands-on sessions.
Course Duration information:
Online training:
- Duration of 15 sessions.
- 2 hour per day.
Weekend training:
- Duration of 5 Weekends.
- Class held 2 days per week on Saturday, Sunday.
- Note: Each session of 3 hours.
3. Will there be any lab facility available for me?
Yes, our lab facility at KnowledgeHut has the latest version of hardware and software and is very well-equipped. We provide Cloudlabs so that you can get a hands-on experience of the features of Big Data Analytics. Cloudlabs provides you with real-world scenarios can practice from anywhere around the globe. You will have an opportunity to have live hands-on coding sessions. Moreover, you will be given practice assignments to work on after your class.
Here at KnowledgeHut, we have Cloudlabs for all major categories like cloud computing, web development, and Data Science.
1. How will I perform the Big Data Analytics practicals at home if I take an online course?
We provide our students with Environment/Server access for their systems. This ensures that every student experiences a real-time experience as it offers all the facilities required to get a detailed understanding of the course.
If you get any queries during the process or the course, you can reach out to our support team.
2. Who will be my faculty?
The trainer who will be conducting our Big Data Analytics certification has comprehensive experience in developing and delivering Big Data applications. He has years of experience in training professionals in Big Data. Our coaches are very motivating and encouraging, as well as provide a friendly learning environment for the students who are keen about learning and making a leap in their career.
3. Can I attend a demo session before enrollment?
Yes, you can attend a demo session before getting yourself enrolled for the Big Data Analytics training.
1. What are the payment options?
We accept the following payment options:
- PayPal
- American Express
- Citrus
- MasterCard
- Visa
2. Do you offer a money-back guarantee for the training program?
KnowledgeHut offers a 100% money back guarantee if the candidates withdraw from the course right after the first session. To learn more about the 100% refund policy, visit our refund page.
3. Can I cancel my enrolment? Do I get a refund?
If you find it difficult to cope, you may discontinue within the first 48 hours of registration and avail a 100% refund (please note that all cancellations will incur a 5% reduction in the refunded amount due to transactional costs applicable while refunding). Refunds will be processed within 30 days of receipt of a written request for refund. Learn more about our refund policy here.
Frequently Asked Questions
1. What is Big Data?
Big Data refers to large amounts of structured and unstructured data that can be analysed using traditional databases and multiple software techniques to reveal patterns that can be used to meet business objectives. Analyses of such large amounts of unstructured data helps in understanding and predicting human behaviour and solving complex business problems. Big Data is huge and consists of complex data sets that traditional data processing software cannot manage.
2. Why is Big Data important?
Big data contains in it patterns and information which when mined can given an insight into customer behavior and preferences. This leads to new innovations, satisfied customers, smoother operations and higher profits. Let’s see the attributes that are making Big Data so popular today:
- Reduced Cost:
With the help of Big Data technologies like Hadoop and cloud-based analysis, organizations find out more efficient ways of doing business and bring cost advantages when it comes to storing huge amounts of data.
- Quick & Improved Decision Making:
With the help of Hadoop and in-memory analytics, organizations can quickly analyze the data and will be able to make decisions based on their learnings.
- Latest products and services:
Big Data helps businesses gauge customer requirements and preferences, based on which they can develop new products or improve existing products to meet customer needs.
3. How does Big Data Analytics work?
Tons of data are generated every second from our activities on social networks, the internet, or even from traditional business systems. This data generated from various sources is very complex and unstructured, and requires analysis to make it useful.
Data Analytics technologies provide organizations the means to analyse the data and draw conclusions, which further helps them improve their business models and create a better experience for their customers. Big Data Analytics is an advanced form of analytics which involves several elements like statistical analysis, what-if, and predictive models. There are a lot of tools and applications that enable analysts and data scientists to analyse different forms of data that cannot be handled by the usual BI applications.
1. Why do we require Big Data technology?
Big Data technology is used to store, retrieve and analyze large amounts of data to reveal hidden patterns, correlations, and other company-related insights. Big Data technology stacks help analyze data faster and help come up with better strategies to develop products that meet the customer’s requirements. Big Data analysis provides several advantages such as:
- Make correct business decisions
- Perform efficient operations
- Higher profits
- Ensure happy and satisfied customers
2. What is the main use of Big Data?
Big Data is used to discover hidden patterns, market trends and customer preferences. These in turn help organizations make informed business decisions, innovate products to meet customer preferences, cut costs, enhance efficiency and reduce time to market.
3. Why is Big Data so popular?
Data is the new oil and Big data is all about helping organizations beat competition and ensure market survival. In this volatile market where costs are hitting the roof and customers are volatile, it is important that businesses understand the pulse of the market and come up with innovations that meet the customers needs while also being cost, process and time efficient. The analyses of Big Data helps do all of that, and also helps in cost reduction and better decision making, which is why it has become indispensable to organizations.
4. What are the benefits of using Big Data?
Big Data analytics is indeed a revolution in the field of IT. It helps organizations to harness their data and use it to identify new opportunities and gain an insight to run their business efficiently. Companies can improve their strategies by keeping in mind customer preference. For example, Netflix Uses Big Data to Improve their Customer Experience.
1. How do I learn Big Data Analytics?
There are many ways to learn Big Data Analytics. You can learn through tutorials, blogs, articles, books, etc. But the best way to learn about Big Data Analytics is by attending a training. The training will equip you with the skills to make a career shift to a promising field.
2. What are the various resources to learn Big Data Analytics?
Below are the various resources to learn Big Data Analytics:
Big Data Course
Big Data Tutorials
Big Data Books
- Analytics India
- The Human Face of Big Data
- Big Data: Principles and best practices of scalable realtime data systems by Nathan Marz and James Warren
- Probabilistic Data Structures and Algorithms for Big Data Applications by Andrii Gakhov
Blogs, articles
3. Do I need to know programming languages to learn Big Data Analytics?
Yes, you need to have a good understanding of programming languages to learn Big Data Analytics.
1. How do I become a Big Data Analyst?
To become a Big Data Analyst, you can take up the Big Data Analytics course. The course will help you understand the fundamentals and basics of Apache Hadoop and data ETL, ingestion, processing with Hadoop tools. Learn and understand the Pig framework and Hive framework. Moreover, you will get the opportunity to work on real-world projects as the course is curated by industry experts.
2. Who provides the Big Data Analytics training?
If you have not added Big Data Analytics skills to your resume yet, then this is the best time to do so. KnowledgeHut provides Big Data Analytics courses that have been crafted by experts which focus on job-readiness and hands-on skills. Build your concepts from scratch and assist your learning through step-by-step guidance on tools and techniques.
3. How long is the Big Data Analytics Certificate valid for?
The Big Data Analytics course completion certificate by KnowledgeHut has lifetime validity.
1. How will this Big Data Analytics training help me in getting a job?
Attending this Big Data Analytics training will help you in getting a job in the following ways:
- It will increase the possibility of landing highly-coveted roles and increase the likelihood of you getting hired.
- It will make you eligible for various domains such as e-commerce, government, finance, healthcare, etc.
- Obtaining certification for the same defines your credibility as it stands as a validation of your skills.
- Enjoy an Increase in salary as your experience grows.
- It helps you stay updated with the latest industry trends.
- Will provide you with an improved career path.
2. What are the career benefits of learning Big Data Analytics?
Big Data Analytics expertise will benefit you in the following ways :
- Helps you gain problem-solving skills
- New opportunities for skilled professionals in a variety of industries like aviation, finance, e-commerce, etc.
- You can select any career path such as project management, security, system architecture, banking etc.
- Increase in salary as the experience grows.
3. What is the future of Big Data Professionals?
According to IDC, worldwide spending on big data and analytics is growing at a compound annual growth rate (GAGR) of 11.9 percent, and revenues will likely total more than $210 billion by 2020. This growth will only increase in the coming years as more and more data gets generated and the need to analyse it for business benefits increases. This has led to an increased demand for data scientists, analysts, and data management experts. Moreover, according to IDC, big data staffing shortage is expected to expand from analysts and scientists to include architects as well as experts in data management. Hence gaining expertise in this domain is sure to help you reap rich dividends in the future.
4. What will be the end result of doing this Big Data Analytics course?
By the end of this course, you will learn about Big Data and Big Data Challenges. You will also gain knowledge of the Hadoop Daemon Processes, HDFS, Hadoop Installation Modes, and HDFS, Hadoop Developer Tasks, Hadoop Ecosystems, Data Analytics using Pentaho as an ETL tool.